基础
JS
作用域
闭包
事件冒泡和拦截
原理
事件冒泡和拦截是两个阶段,它们都和 DOM 树的事件传播有关系。当我们对某个节点触发事件时:
- 首先会触发事件捕获
- 事件会从文档的根节点一级级传到当前的节点
- 接着是事件冒泡
- 事件会从当前节点一级级向上传到文档的根节点
基于这些机制,我们可以做一些处理:
- 比较常见的是事件委托,事件委托是一种处理方式,它利用冒泡机制可以减少内存的使用。比如有一个列表有 n 个节点,每个节点都有点击事件,如果对每个节点都绑定点击事件,需要不少内容。但我们可以通过冒泡机制,在它们的父节点进行绑定点击事件,根据返回的 event 对象去判断是点击了哪个节点。这样只需要绑定一个事件就行了
- 在遮罩层阻止事件传播
addEventListener
- Passive
- 设置为 true 时,当前的事件在 wheel, mousewheel, touchmove 等会使页面滚动的事件,不会阻断页面的渲染
- 当事件内有调用
event.preventDefault(),则当前设置无效 - 可以基于该属性对页面滚动进行一定的性能优化
- capture
- 是否执行拦截
- once
- 调用一次后,该绑定事件自动取消
- signal
- 传入 AbortSignal 实例,用于控制取消事件
什么是 AbortController
- 可以阻止 featch 的请求
- 可以移除 addEventListener 的事件
xhr 如何阻止请求?
可以
// 创建 XMLHttpRequest 对象
const xhr = new XMLHttpRequest();
// 设置请求完成时的回调函数
xhr.onreadystatechange = function () {
if (xhr.readyState === 4) {
if (xhr.status === 200) {
console.log("Request successful:", xhr.responseText);
} else if (xhr.status === 0) {
console.log("Request was aborted");
} else {
console.log("Request failed with status:", xhr.status);
}
}
};
// 初始化请求
xhr.open("GET", "https://example.com/data", true);
// 发送请求
xhr.send();
// 在需要取消请求时调用 abort 方法
xhr.abort();参考资料
- [addEventListener](https://developer.mozilla.org/en-US/docs/Web/API/EventTarget/addEventListener#syntax
- AbortController
继承和原型链
内存管理
事件模型
类型数组
Vue
Vue2 和 Vue3 的区别
watch 和 computed 的区别和实现
Vue3 为什么要使用 proxy ?
为什么要 proxy + reflect 搭配使用?
reflect 的使用,是为了解决 this 指向问题。
举例,对象有一个 get 访问器的 b 属性,它通过 this 访问该对象的 a 属性,而副作用函数会读取代理对象的 b 属性,这样会使副作用函数对 a 属性进行依赖收集。因为 b 属性是一个访问器属性,并且返回的是 a 属性。如果不使用 reflect 的话,因为 proxy 的 get 拦截器中的第一个参数 target,是原始对象,这会导致的结果就是副作用函数是喝原始对象的 a 属性进行依赖,是没有响应能力的,所以这里我们要返回的的是代理对象的值。
javascriptconst obj = { a: 1, get b() { return this. a } } effect(() => obj.b) // not working proxyObj.a++reflect 方法有三个参数:目标对象、key、是要操作的对象,我只需将 proxy.get 的第三个参数传给 reflect 就行了
为什么 proxy.get 不能返回 receiver[key] 呢?
因为 receiver 就是代理对象,当你返回 receiver[key] 时,又会触发 proxy.get,这时候就会出现死循环
为什么会有 ref 的存在?
因为 JS 无法对原始值进行代理操作,所以需要包裹一层转换为对象,从而间接对该原始值进行代理
而 ref 函数就是做这个包裹的操作,所以要读取代理原生值后的值,就要访问 ref 执行后的 .value
并且里面使用了 Object.defineProperty 来定义了一个 __v_isRef 的内置属性,来声明这是一个 ref 标识
为什么 ... 解构操作会导致响应丢失?如何解决
因为解构操作相当于对对象重新赋值,它只是读取对象的值,而不是引用对象,不具有响应能力
Vue 提供了 toRef 和 toRefs 函数,原理是根据对象和对应的 key 返回一个新的对象,并且对新对象设置了 [get] 访问器,当读取新对象对应的 key 的值时,就会访问原始响应对象的 key 的值
为什么 Vue3 可以多个根节点?
内部使用了 fragment 节点。在 DOM 中,fragment 节点渲染到 HTML 时是不会渲染的,它是一个虚拟节点
nexttick 原理
Vite.js
优点:
- 依赖浏览器对 esm 规范的支持,不对文件进行 bundle 操作,可以直接在浏览器通过 import 方式访问各个文件;基于这个原理,使项目启动和更新可以快速完成
- 集成了 rollup ,依赖 rollup 的生态,无需造更多的轮子
- 底层使用了 esbuild ,在开发时进行代码的转换
缺点:
- 因为使用了 import 语法,不支持 ie 或低版本的浏览器。但可以通过构建传统资源的方式去解决
- 当应用文件很多的时候,访问页面会发起大量的 http 请求
- 生态虽然是依赖 rollup,但没 webpack 丰富
Rollup
- Rollup 是一个 js 的模块打包器。它是基于 esm 规范对文件进行打包处理
- 它可以使用插件去支持 commonjs 规范的文件
- rollup 默认就支持 tree-shaking,它可以轻易地打包更小更轻的文件
为什么需要 esm 规范才能支持 tree-shaking?
什么是 tree-shaking?
打包时清除不会被执行的代码、不会使用到的代码
因为基于 esm 规范的代码,工具可以进行静态分析去获取依赖关系,从而进行 tree-shaking。如果是 commonjs 规范,它是可以动态引入的
为甚生产模式不用 esbuild?
- 生产环境下需要更多的优化:虽然 esbuild 速度非常快,但在生产环境下,我们需要更多的代码优化和压缩,以减少代码大小和加载时间。而 Rollup 在这方面更加成熟,可以进行更多的代码优化和压缩。
- Rollup 更适合于打包和构建:尽管 esbuild 可以进行模块打包和构建,但是 Rollup 的打包和构建能力更加全面和成熟。而 Vite 在生产模式下默认使用 Rollup 进行打包,可以方便地对代码进行压缩、混淆和分离等操作,从而减少代码大小和提高性能。
- 兼容性问题:esbuild 采用的是最新的 JavaScript 标准,对一些旧版本的浏览器可能不太友好。而 Rollup 则可以对代码进行更好的兼容性处理,以适应不同的浏览器环境。
参考资料
commonjs, esm import 等区别
cjs (commonjs)
Commonjs 规范是起源于早起的 Node.js 模块化方案,它使用 require 和 module.exports 来实现文件的引入和输出
commonjs 规范支持动态引入,可以在运行时使用 require 进行引入文件
esm (es module)
esm 是 Ecmascript 定义的新的模块化规范,使用 import 和 export 来实现文件模块化
Esm 是静态导入的依赖的,通过 import from 的语法,依赖只能说静态的字符串,如果需要动态引入依赖,可以使用 import 的全局方法,
因为 esm 是静态导入的,所以它支持 tree-shaking
特点
1.module默认是defer的加载和执行方式
2.这里会存在单独的module的域不会污染到全局
3.直接是strict
umd
一种兼容 cjs 与 amd 的模块,既可以在 node/webpack 环境中被 require 引用,也可以在浏览器中直接用 CDN 被 script.src 引入。
commonjs 和 import 如何解决循环依赖的问题?
commonjs
Modules are cached after the first time they are loaded. This means (among other things) that every call to
require('foo')will get exactly the same object returned, if it would resolve to the same file.模块在第一次加载后被缓存。这意味着(除其他事项外)每次调用 require('foo') 都将返回完全相同的对象,如果它解析为同一个文件的话。
demo:
// a.js
const { b } = require("./b");
const a = 11;
console.log('b in a.js', b);
module.exports = { a };
// b.js
const { a } = require("./a");
const b = 12;
console.log('a in b.js', a);
setTimeout(() => {
console.log('a in b.js', a);
}, 1000);
module.exports = { b };
// c.js
const { a } =require("./a.js")
console.log('ccc:', a);
// index.js
require('./a.js')
require('./c.js')解决:先 module.exports,再 require 变量
esm
esm 是不支持循环依赖的。当浏览器检测到有引入未初始化完成的文件时,会抛出错误:
Uncaught ReferenceError: Cannot access 'a' before initialization项目
Base
Npm
生命周期
npm script hooks
![[npm 基础概念#Npm script 执行流程]]
私有搭建
![[npm 基础概念#Npm 私有源的搭建]]
Monorepo & Turborepo
什么是 Monorepo?
![[monorepo#什么是 Monorepo]]
除了 monorepo 还有什么架构?
- 单体架构,一个代码仓库只有一个应用或包
- 多仓库架构,每个应用和包,都是独立的一个代码仓库
- 如果应用和包之间有互相引用,在开发时就很麻烦,需要不断地打包、发布、安装新的依赖
- 多分支架构,在一个代码仓库中,用分支去管理不同的模块开发
什么时候要用到?
![[monorepo#什么项目应该用?]]
Turborepo 是什么?
Turborepo 是 Vercel 公司研发的一个 monorepo 工具,它主要是提供了缓存功能、脚本任务编排和并发执行等功能
但这个工具是不提供有关 workspace 依赖安装的功能,所以需要 npm, yarn 或 pnpm 来实现 monorepo 中依赖的安装和链接
为什么用它?用了什么点?带来什么好处?
我用它的时候是在 21 年中旬左右,那时候原本打算是用 lernajs,但看了下它在 github 的维护情况,好像一年多都没维护了,而且很多 issues,以为这工具没人维护了,所以用其他的 monorepo 工具,就找到了 turborepo。
- 我按照它的文档,很快就能上手,
- 当时候看中了它的脚本任务并发执行,比如我执行 npm run test 时,包之间没有依赖的情况下,就可以并发执行,提升执行效率
- 而当时的 lernajs 它是不支持任务依赖关系的编排,比如 b 任务需要等 a 任务完成了再执行
![[monorepo#优缺点]]
低代码引擎
什么是低代码引擎?
它是一个开发应用的平台,通过可视化的界面、拖拽交互和在线代码的编写,可以快速地预览、构建和发布应用,提升交付效率和减少开发成本
什么是无代码引擎
在低代码引擎的基础上,隐藏了在线代码编写的功能,通过更加抽象和封装,让用户通过界面交互就可以完成应用的开发
如何设计低代码引擎的?
在清楚了业务目标和业务需求的情况下
- 该工具在什么终端运行?桌面端还是网页端?
- 目标用户是谁
- 这个应用的输入和输出是什么
- 输入有内置的组件、用户交互后得到的数据
- 输出是用户编辑后的应用数据和基于应用数据生成的前端工程代码
- 这个应用的拓展性如何设计
有没有遇到什么难点?
如何使编辑时和生产运行时显示的页面效果保持一致?
TODO
工程化的搭建
该引擎的可拓展性如何设计?
整个引擎,可以自由地注册你需要用到的组件,只需要按照我们提供的 typescript 定义去进行开发和输出,比如现在我们已经有三种类型的组件:一个是基础组件,提供基础模块,比如表单控件、表格、文字、按钮等常用组件;一个是图表组件,基于 echart 进行封装;最后一个是业务组件,专门用于某个业务项目的
组件的开发是基于配置 + 代码的方式,在我们的低代码引擎,会根据当前选中组件的配置,去生成相关的设置器,让用户对组件进行属性、事件的修改
并且我们还内置了全局变量、工具函数的编写和数据源功能,尽量让用户可以控制应用的每一处地方
前端埋点
是什么?
在前端代码添加相关的逻辑,当应用有变更或有用户操作,对那一刻进行一些数据的收集,并存储到对应的服务中。然后开发者可以在管理后台看到相关的统计数据和详细数据,看到应用的使用情况、用户行为、代码错误等
如何进行错误捕获?
Js 的语法总体分为两种:语法错误和运行时错误
语法错误是无法捕获的,因为它是在编译时发现的,这个只能使用 TypeScript 和 EsLint 等工具进行静态分析
运行时错误分为:
- 同步错误
- 异步错误
- Promise 错误
- 资源加载错误
常见的 js 错误捕获方法有:
try...catch
window.addEventListener('error', (e) => {
console.log('error', e);
})
window.addEventListener('unhandledrejection', (e) => {
console.log('unhandledrejection', e);
})| 同步错误 | 异步错误 | Promise错误 | 资源加载错误 | |
|---|---|---|---|---|
| try catch | y | y | ||
| error | y | y | y | |
| unhandledrejection | y | y | ||
| Vue的全局捕获 | y | y | y |
参考资料
采取什么方式上传?
- 接口
- 优势
- 简单
- 可以上传大数据
- 缺点
- 容易出现跨域问题
- 优势
- 图片请求
- 优势
- 能够完成整个 HTTP 请求+响应(尽管不需要响应内容)
- 触发 GET 请求之后不需要获取和处理数据、服务器也不需要发送数据
- 跨域友好
- 执行过程无阻塞
- 相比 XMLHttpRequest 对象发送 GET 请求,性能上更好
- GIF的最低合法体积最小(最小的BMP文件需要74个字节,PNG需要67个字节,而合法的GIF,只需要43个字节)
- 缺点
- 不支持大数据上传
- 15k 左右的数据 chrome 就会返回 431
- 优势
- sendBeacon
- 浏览器的 API,用于发送异步的 POST http 请求,不会阻断页面关闭或跳转
- 不会阻塞页面,只能发送大数据,视当前浏览器限制,目前最大是 64kb
cli 工具库
husky
commander
- 是一个命令行解析工具,可以解析你在命令行执行的内容,并且可以生成文档
- 实现原理
- 使用 Node.js 内置的
process.argv数组来获取用户输入的命令行参数,包括了用户执行的命令、选项和参数等 process.argv会根据你的输入,使用空格进行切分成一个字符串数组,第一个参数是 node 程序的绝对路径,第二个参数是当前被执行文件的绝对路径,然后就可以根据你定的规则进行相关解析,比如第三个参数作为要执行的命令,从四个参数开始,作为第三个参数的选项参数
- 使用 Node.js 内置的
inquirer
- 是一个可交互的 cli 库,可以让用户进行内容输入、选择等普通的表单操作
- 实现原理
- 使用 nodejs readline 模块来实现;readline 是用于处理命令行的输入输出命令,可以基于它的 接口来实现内容显示、用户输入、选择等功能
ora
![[ora#原理]]
chalk
![[chalk#原理]]
changeset
demo - inquirer
inquirer 实现 demo:
const readline = require('readline');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
const options = ['Option A', 'Option B', 'Option C'];
let selectedOption = 0;
function printOptions() {
for (let i = 0; i < options.length; i++) {
if (i === selectedOption) {
// 使用 ANSI 转义序列高亮当前选择项
readline.cursorTo(process.stdout, 0, i);
readline.clearLine(process.stdout, 0);
process.stdout.write('\x1b[33m' + options[i] + '\x1b[0m');
} else {
readline.cursorTo(process.stdout, 0, i);
readline.clearLine(process.stdout, 0);
process.stdout.write(options[i]);
}
}
}
printOptions();
rl.input.on('keypress', (key, info) => {
if (info.name === 'up') {
if (selectedOption > 0) {
selectedOption--;
printOptions();
}
} else if (info.name === 'down') {
if (selectedOption < options.length - 1) {
selectedOption++;
printOptions();
}
} else if (info.name === 'return') {
console.log(`You have chosen ${options[selectedOption]}.`);
rl.close();
}
});业务组件库
什么是 sso
单点登录,是一种用户身份验证机制,允许用户只需登录一次就能够访问多个相互信任的应用系统
我们这边的实现流程是这样的:
- 开发一个 sso 的网页应用,当访问业务系统时,会检测当前的登录状态,如果未登录或登录失效,就会携带当前 url 和业务系统信息重定向到 sso 应用
- 然后 sso 应用会根据当前的 localStorage 来检测是否要重新登录,如果不需要,就会生成新的 ticket ,然后再重定向到业务系统,业务系统就会根据 ticket 去获取一个临时 token,进而获取登录信息
- 如果 sso 检测需要登录,就登录,然后再走刚刚的流程
总结来说,就是 sso 应用来判断用户是否要重新登录,然后发放 ticket 来让业务系统去获取 token。这个 ticket 是有很短的时效性并且只能用一次。
通过 ticket 机制防止 token 的丢失
缓存的页签组件的实现
- 主要是利用 Vue 提供的 keep-alive 组件实现
- 该组件是利用组件的 name 属性作为 key 进行缓存的,被设置为缓存后的组件,当它要进行卸载时,它不是走正常组件的卸载流程,比如触发 unmouted 的声明周期事件;vue 内部会调用 unactived 事件,并将组件存储在某地方从而实现缓存功能
- 给渲染的 Component 组件添加
:key="route.fullPath",实现可以缓存同一组件但不同路由的页面 - 给
keep-alive组件添加:include属性,控制缓存哪个页面 - 使用一个包裹组件和
:key属性,用于控制刷新目标组件,解决缓存同一组件但不同路由的页面下的缓存异常问题
问题1 - 如何缓存同一个组件不同的页面?
通过在 component 组件添加 :key="route.fullPath" 来解决
问题2 - 缓存同一个组件不同的 url 页面,如何移除某个页面时不影响其他同组件页面的缓存?
request 封装
- 我是封装成一个可定制的包裹函数,就类似柯里化那种,业务系统可以预设一些条件,比如 code 返回什么值才代表是成功的?你的错误提示、loading 效果是怎么显示的,预设一些参数、头部信息、如何自定义接口返回的数据,将这些配置传进包裹函数就会返回一个 request 实例
- 而这个包裹函数我们还内置一些默认的功能,比如接口的埋点上报、默认的逻辑处理等
这个封装相当于把部门内部比较基础的逻辑处理都放进去,但业务系统也可以个性化的配置
EggJs
是阿里开源的一款基于 koa2 的 Node.js 框架,它提供了齐全的一些功能和完整的使用文档,可以快速上手
比如数据库的插件、日志、监控等功能
MongoDb
是什么?
是一款 NoSql 的数据库,它是基于 JSON 格式的文档,所以它能拓展任意字段和进行文档嵌套,非常得灵活
并且它是使用内存映射文件的方式来管理数据,相当于直接读写内存,所以它的性能很不错
什么是 nosql
是一种非关系型数据库管理系统,它更加灵活、可扩展、高性能,能够处理大量的非结构化或半结构化数据
什么是内存映射文件?
内存映射文件(Memory-mapped Files)是一种将文件映射到进程的地址空间的技术,可以将文件内容直接映射到进程的虚拟内存中,使得进程可以像访问内存一样访问文件内容,从而实现高效的文件读写操作
-- chatGPT
总结下:
通过操作系统提供的 mmap() 系统调用实现的。
当进程打开文件并调用 mmap() 函数时,操作系统会为该文件分配一段连续的虚拟内存空间,并将该空间映射到文件的物理地址空间中。这样,当进程读取或写入内存映射文件时,就相当于直接读取或写入文件,而不需要进行繁琐的文件操作
MongoDB 还提供了一个特殊的文件“journal”(日志文件),用于记录所有的写操作。这样,即使出现系统崩溃或故障等情况,MongoDB 也可以使用 journal 日志文件来恢复数据,保证了数据的可靠性和一致性
同时会出现一些缺点:
- 内存占用高
- 不适用于频繁的修改操作
- 文件过大的限制
- 数据的一致性问题s
聚合管道是什么?
是一种数据处理方式,基本原理是将多个聚合操作依次串联起来,每个操作处理输入数据并将结果传递给下一个操作,可以进行筛选、分组、计算、排序等等,可以形成一份复杂的数据
聚合管道的优点包括:
- 灵活可扩展:聚合管道的聚合操作可以任意组合,可以根据实际需求进行自由拼装,形成一个灵活可扩展的聚合框架,支持复杂的数据处理和分析操作。
- 高效性能:聚合管道通过将多个聚合操作串联在一起,可以将多次操作合并为一次操作,从而减少了数据库操作的次数,提高了数据处理的效率和性能。
- 易于使用:聚合管道的聚合操作符基本上与 SQL 语句中的聚合操作类似,因此对于熟悉 SQL 的开发人员来说,使用聚合管道非常容易上手。
总之,聚合管道是 MongoDB 中一个非常强大和灵活的数据处理工具,提高了数据处理的效率和性能。
MongoDB 聚合管道的缺点主要包括以下几点:
- 资源占用:聚合管道在处理大量数据时,需要占用大量的系统资源,例如 CPU、内存等,可能会导致系统性能下降甚至崩溃。
- 复杂性:聚合管道由多个聚合操作组成,需要开发人员熟悉每个聚合操作符的语法和用法,并且需要合理组合各个聚合操作,才能实现预期的数据处理效果。因此,聚合管道的使用具有一定的复杂性。
- 不支持事务:MongoDB 的聚合管道不支持事务操作,因此在使用聚合管道进行数据处理时,需要注意事务性和数据一致性的问题。
- 性能问题:聚合管道需要在 MongoDB 中进行多次查询和计算,可能会导致性能瓶颈问题,例如聚合操作过程中需要频繁的磁盘读写操作,从而影响查询效率和性能。
DevOps
什么是 DevOps
它是一种方法论,将软件开发和运维进行紧密地结合,比如从软件的开发、测试、构建、发布到运维的整个过程中,通过自动化、ci、cd 等技术,提升软件的交付效率和保持稳定性
那你这个 DevOps 工具平台有什么特点?
整个项目从开发到现在,主要是偏向开发这边的,比如 API 的管理、运行、Mock、测试,代码模板,低代码引擎,元数据管理等功能;然后由一个自研的 shell 脚本编排和执行的功能,用于代码的构建、发布、回滚等操作
Electron
什么是 Electron
Electron是一个使用 JavaScript、HTML 和 CSS 构建桌面应用程序的框架。 嵌入 Chromium 和 Node.js 到 二进制的 Electron 允许您保持一个 JavaScript 代码代码库并创建 在Windows上运行的跨平台应用 macOS和Linux——不需要本地开发 经验。
优点:
- 适合 JavaScript 体系开发,上手简单,可以构建多个平台的应用
- 框架成熟,有不错的生态,有很多成功的桌面应用,比如 VsCode 和 Postman
缺点:
- 体积大,占用内存大,因为集成了 Chromium 和 NodeJS
- 性能没有原生好
如何实现应用的自动更新?
- 因为这个是桌面端的应用,它是需要 Window 和 MacOs 环境下进行打包的,要构建两次的,所以我是用 Node.js 编写脚本的方式,进行代码自动化的构建和上传的
- 使用 electron-builder 库对应用进行构建和相关平台的签名验证
- 使用 electron-updater 库实现应用更新检测、下载和更新功能
- 并且实现一个文件上传和下载的服务,提供给 electron-updater 使用;每当用户打开应用或者调用检测更新接口时,会根据当前应用的版本和服务的最新版本进行比较来判断是否要更新
如何进行版本比较?
可以使用 semver 比较两个版本号的大小
Api Mock 实现
- 在 DevOps 实现了 API 的管理功能,里面的每个 API 都有接口方法、路径、请求参数、响应结构等 http 请求需要的数据
- 当用户发起 Mock 请求时,我们会根据请求地址的路径、方法找到对应的 api 结构化的数据
- 然后系统会根据那份数据 + MockJs 实现假数据的生成
- 并且我们还支持对字段进行 mockjs 的模板预设,比如 name 字段,可以选择某个 mockjs 提供的预设,比如返回中文名称等,去丰富返回的数据内容
- 我们的 Mock 还支持复杂的业务场景,比如一个业务激活警用的流程,访问一个详情接口,前后的状态会有变化,我们可以对 api 进行添加 mock 模板,设置命中条件和触发器,来实现这个场景,
Shell 流水线功能的实现
- 这个 shell 脚本流水线执行功能,我们实现了一个调度执行的逻辑,去触发对应的 shell 集合
- 首先有个任务管理的功能,去让用户可以添加、编辑多个 shell 脚本,并且脚本支持变量的功能,可以在这个任务中随意添加任意的变量
- 然后对应的工程会选择某个任务去进行相关的构建、发布、回滚等操作。而我们的服务就根据用户传入的参数然后去执行任务中里每个脚本。并且用户可以随意选择任务中的脚本在哪台服务器执行,而这里是用 ssh 连接来实现的
使用 shelljs 这个库去实现,这个库里面其实就是基于 nodejs 的 children 模块封装的
NestJs
NestJs 接口访问的整个流程:
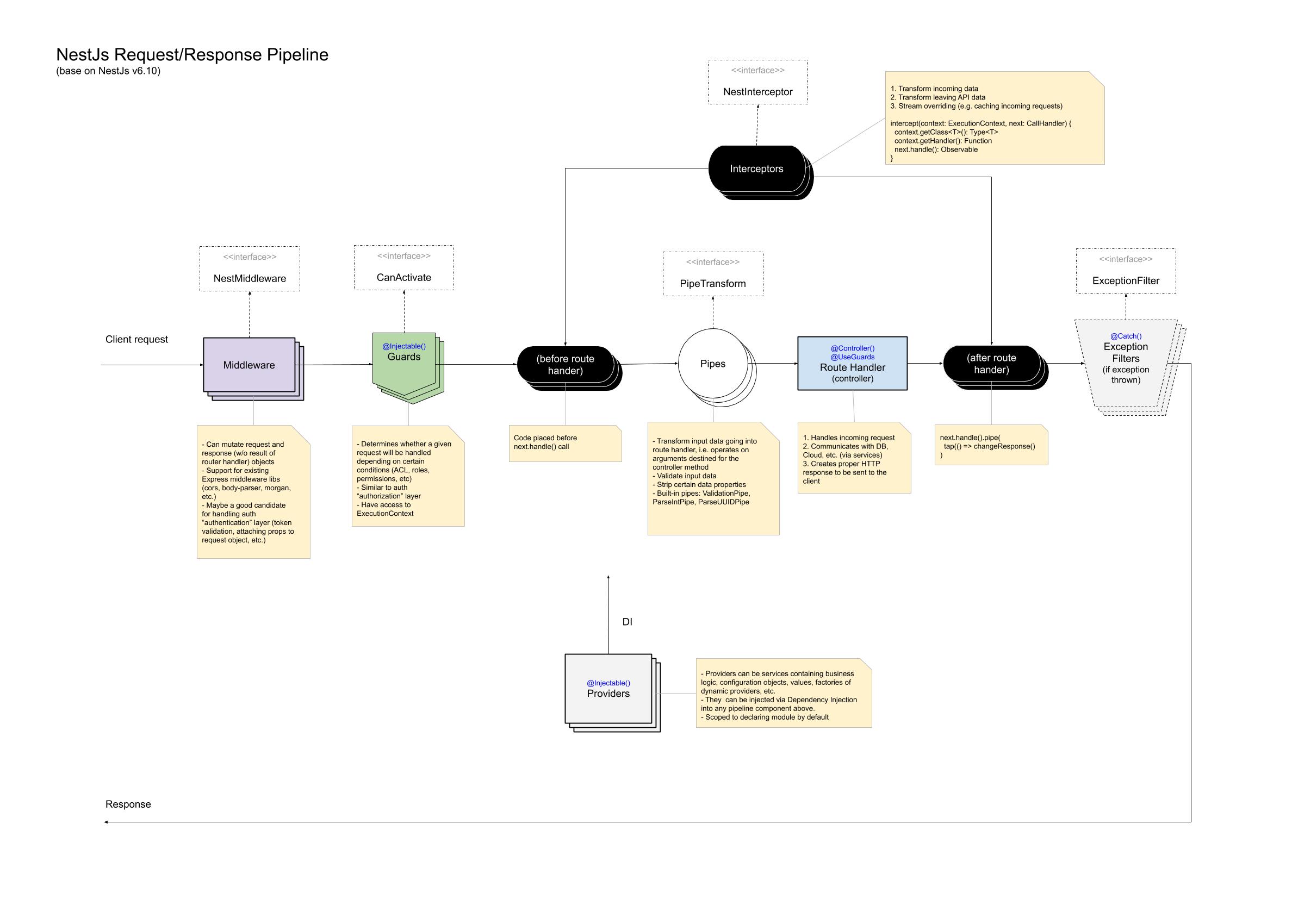
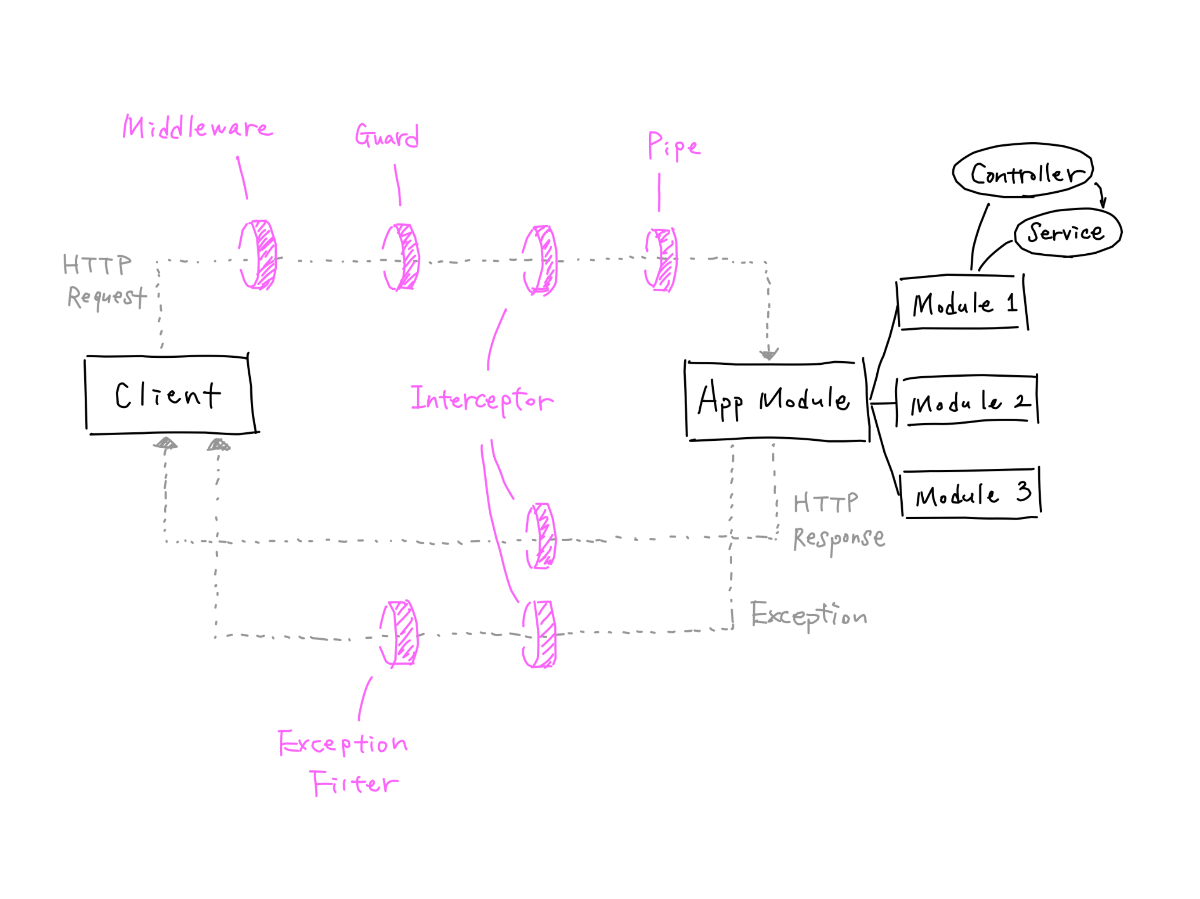
为什么 nestjs 会有管道、拦截器、中间件和守卫等类似的功能
请求的生命周期
- Incoming request
- Globally bound middleware
- Module bound middleware
- Global guards
- Controller guards
- Route guards
- Global interceptors (pre-controller)
- Controller interceptors (pre-controller)
- Route interceptors (pre-controller)
- Global pipes
- Controller pipes
- Route pipes
- Route parameter pipes
- Controller (method handler)
- Service (if exists)
- Route interceptor (post-request)
- Controller interceptor (post-request)
- Global interceptor (post-request)
- Exception filters (route, then controller, then global)
- Server response
什么是 aop(面向切面编程)
它是一种编程范式,通过不修改原逻辑的情况下加入一些新的功能。在 NestJs 是使用装饰器来实现,比如我可以对某个 controller 的方法添加一个 usePipe 或 useGuard 来进行数据处理和校验,这种添加方式不会修改原有代码
什么是 ioc (控制反转)
是一种设计模式,将组件之间的关系进行解耦,提高组件的可重用性、可扩展性等
组件之间的依赖关系由容器来管理,容器会负责创建和管理组件,组件只需要声明自己所需要的依赖,由容器来注入相应的实现
而依赖注入是它的一种实现方式
什么是 NestJS?你为什么要使用 NestJS?
NestJS 是一个基于 Node.js 平台的 Web 应用程序开发框架,使用 TypeScript 编写并采用了一系列现代化的编程技术,如依赖注入、面向切面编程、函数式编程、反应式编程等。使用 NestJS 可以更快、更轻松地开发可扩展、可维护的 Web 应用程序。
什么是依赖注入(Dependency Injection)?在 NestJS 中,你是如何使用依赖注入?
依赖注入(Dependency Injection,DI)是一种设计模式,用于解耦组件之间的依赖关系,提高代码的可维护性、可测试性和可复用性。
依赖注入的基本思想是,将一个对象所依赖的其他对象的实例(即依赖)在创建该对象时由外部环境提供,并通过构造函数、方法或者属性等方式将依赖注入到对象中,从而降低对象与依赖之间的耦合。
在 NestJS 中,通过将 Providers 提供给 NestJS 容器,容器会自动管理 Providers 的生命周期,并在需要的地方将它们注入到需要的组件中。使用依赖注入可以让我们更加专注于实现组件的功能,而不用过多关注依赖组件的创建和管理。
总之,依赖注入是一种非常有用的设计模式,可以提高代码的可维护性、可测试性和可复用性,而在 NestJS 中,依赖注入是一个核心概念,它的使用和实现贯穿于整个框架的设计和实现中。
什么是模块(Modules)?NestJS 中的模块是如何工作的?
模块是 NestJS 应用程序的基本组成单元,用于组织应用程序中的组件、路由器和提供者等资源。每个 NestJS 应用程序至少有一个根模块,其他模块可以在根模块中引入或者在其他模块中引入。模块可以定义提供者、控制器和管道等组件,并且可以通过导出这些组件来使其他模块使用它们。
依赖注入是一种设计模式,用于解耦和组织应用程序中的组件。在 NestJS 中,可以使用 @Injectable() 装饰器来定义一个可注入的服务(Service),然后在控制器(Controller)或其他服务(Service)中通过构造函数参数来注入这个服务。
什么是提供者(Providers)?NestJS 中的提供者有哪些类型?它们的作用是什么?
- 提供者是 NestJS 应用程序中的组件,它们用于实现各种功能,比如数据库连接、服务调用、日志记录等。NestJS 中的提供者有以下几种类型:
- 服务(Services):封装业务逻辑和与数据库交互等操作;
- 控制器(Controllers):处理客户端请求和响应;
- 管道(Pipes):对请求参数进行预处理或者过滤;
- 守卫(Guards):保护路由或者控制器的访问;
- 拦截器(Interceptors):在请求和响应之间进行拦截和处理;
- 中间件(Middleware):在请求处理过程中进行拦截和处理。
什么是控制器(Controllers)?NestJS 中的控制器是如何工作的?它们与路由(Router)有何区别?
- 控制器是应用程序中处理客户端请求和响应的核心组件,每个控制器都是一个类,其中包含多个动作(Action),用于处理不同类型的客户端请求,并返回对应的响应结果。控制器使用路由(Router)来管理不同的 URL 和 HTTP 动词,并将请求路由到正确的动作。
- 在 NestJS 中,控制器通过装饰器来定义路由和动作。@Controller() 装饰器用于定义一个控制器类,@Get()、@Post()、@Put()、@Delete() 等装饰器用于定义控制器中的动作。控制器中的动作可以返回普通数据、HTML 页面、JSON 格式的数据、文件等各种类型的响应结果。
- 与路由相比,控制器提供了更高层次的抽象和封装,使得应用程序的开发更加简单和易于维护。
什么是服务(Services)?NestJS 中的服务是如何工作的?它们与提供者(Providers)有何区别?
什么是服务(Services)?NestJS 中的服务是如何工作的?它们与提供者(Providers)有何区别?
服务是 NestJS 应用程序中的一个特殊类型的提供者,它主要用于封装业务逻辑和与数据库交互等操作。服务可以被控制器或其他服务注入,并通过接口暴露自己的方法。
在 NestJS 中,可以使用 @Injectable() 装饰器来定义一个服务,然后在控制器或其他服务中通过构造函数参数来注入这个服务。服务可以调用其他提供者来完成自己的功能。
与提供者相比,服务是一种更具体、更具业务含义的组件,通常用于封装一些常用的、通用的功能。
什么是管道(Pipes)?在 NestJS 中,你是如何使用管道来验证和转换输入数据?
- 管道是 NestJS 应用程序中的一个组件,它用于对请求参数进行预处理或者过滤,从而保证请求数据的正确性和安全性。在 NestJS 中,可以使用内置的管道或者自定义管道来实现请求参数的验证和转换。
- 在控制器中的动作参数上使用管道时,可以使用 @Body()、@Param()、@Query()、@Headers() 等装饰器来获取对应的请求参数,并通过 @UsePipes() 装饰器来应用对应的管道。
- 管道可以通过 transform() 方法来实现请求参数的转换,也可以通过 validate() 方法来实现请求参数的验证。管道还可以通过异常抛出来中断请求处理过程。
什么是拦截器(Interceptors)?在 NestJS 中,你是如何使用拦截器来修改请求和响应?
- 拦截器是 NestJS 应用程序中的一个组件,它用于在请求和响应之间进行拦截和处理,可以实现对请求和响应进行修改、转换和记录等功能。在 NestJS 中,可以使用内置的拦截器或者自定义拦截器来实现这些功能。
- 拦截器可以应用于整个应用程序、控制器或者单个动作上,可以通过
@UseInterceptors()装饰器来应用拦截器。在拦截器中,可以通过intercept()方法来处理请求和响应,也可以通过异常抛出来中断请求处理过程。 - 拦截器的一个常见用途是进行日志记录,例如记录每个请求的请求参数、请求时间和响应时间等信息。
什么是中间件(Middleware)?在 NestJS 中,你是如何使用中间件来修改请求和响应?
- 中间件是 NestJS 应用程序中的一个组件,它用于在请求处理过程中进行拦截和处理,可以实现对请求和响应进行修改、转换和记录等功能。在 NestJS 中,可以使用内置的中间件或者自定义中间件来实现这些功能。
- 中间件可以应用于整个应用程序、控制器或者单个动作上,可以通过
app.use()方法或者@Use()装饰器来应用中间件。在中间件中,可以通过req、res和next参数来处理请求和响应,也可以通过异常抛出来中断请求处理过程。 - 中间件的一个常见用途是进行身份验证和授权,例如在请求处理之前验证用户的访问令牌,或者在请求处理之后添加响应头信息。
什么是异常过滤器(Exception Filters)?在 NestJS 中,你是如何使用异常过滤器来处理全局和局部异常?
- 异常过滤器是 NestJS 应用程序中的一个组件,用于处理全局和局部的异常,可以将异常转换为友好的响应格式并进行日志记录。在 NestJS 中,可以使用内置的异常过滤器或者自定义异常过滤器来实现这些功能。
- 可以在控制器、服务、管道和拦截器中通过
throw关键字来抛出异常,异常会被 NestJS 框架捕获并交给异常过滤器来处理。异常过滤器可以应用于整个应用程序或者单个控制器上,可以通过@Catch()装饰器来定义异常过滤器。 - 在异常过滤器中,可以通过
catch()方法来处理异常,并将异常转换为友好的响应格式返回给客户端。异常过滤器还可以通过异常类型、HTTP 状态码、响应头等属性来进行定制化的处理。
PgSql
pgsql 是什么?
pgsql 是一款开源的、关系型数据库。(为什么用它?公司的数据库都是用 pgsql,所以选它)
什么是关系型数据库?
它是一种基于关系模型进行数据管理的系统,使用表格来组织和存储数据。数据以行和列的形式呈现,每个列都定义了数据的类型和长度,并且每一行都代表了一个数据记录。
优点:
- 数据结构清晰
- 数据一致性:关系型数据库支持ACID(原子性、一致性、隔离性和持久性)事务,确保数据的一致性和可靠性。
- 数据查询方便:关系型数据库支持SQL(Structured Query Language),可以方便地进行数据查询和操作。
- 数据安全性高:关系型数据库支持访问控制、用户权限管理、数据加密等安全性控制,保证数据的安全性和隐私性。
- 数据共享易于实现:关系型数据库支持数据共享,不同应用程序可以访问同一份数据,实现数据共享和共用。
缺点:
- 限制:关系型数据库具有固定的表结构,数据必须按照预定义的结构进行存储,不够灵活。
- 性能:性能相对于 Nosql 没那么好,特别是在大型数据查询,涉及到多表关联查询时
- 扩展性:由于关系型数据库的表结构和约束,它的扩展性可能受到一定限制。在需要快速处理大量数据的情况下,可能需要进行分片或使用其他数据库技术。
- 成本:商用关系型数据库的许可证费用通常比较高,而且需要额外的硬件、软件和维护成本。
- 复杂性:虽然关系型数据库使用SQL语言进行查询和操作,但是学习和理解SQL语言需要一定的时间和经验。同时,关系型数据库的设计和管理也需要一定的专业知识和技能。
什么是 acid?
ACID是数据库事务的四个特性的缩写,分别是:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。这四个特性是保证事务处理正确、可靠和高效的基本要素。
- 原子性(Atomicity):指事务是一个原子操作单元,要么全部执行,要么全部不执行。如果事务的任何部分失败,则整个事务将被回滚到原始状态,以确保数据一致性和完整性。
- 一致性(Consistency):指在事务开始和结束时,数据库的状态必须保持一致。这意味着,事务的操作应该满足所有的约束条件和完整性规则,以确保数据的正确性和一致性。
- 隔离性(Isolation):指并发的事务之间应该互相隔离,使它们看起来像是在独立运行。这意味着,在并发情况下,事务应该相互隔离,以避免干扰和冲突,保证数据的准确性和一致性。
- 持久性(Durability):指一旦事务完成提交,它对数据库所做的更改将是永久性的,即使发生硬件故障或系统崩溃,数据也不会丢失。
ACID特性是关系型数据库管理系统的基本特性,它确保数据的完整性和一致性,并提供可靠的事务处理。但是,对于某些需要高并发、高可用和大规模数据存储的应用程序,ACID特性可能会对性能产生一定影响,因此一些NoSQL数据库采用了其他事务模型,如BASE(Basically Available, Soft state, Eventually consistent)模型。
super-app
js-bridge
是一种 Web 和 App 端约定好的一种双向数据通信方式。App 端通过在 WebView 的全局变量中添加协商好的变量和方法,使两者可以互相通信。通过 jsbridge,前端可以调用客户端提供的原生 API,比如直接唤起摄像头、扫描二维码、获取文件数据等等
参考资料
jest
由 facebook 开发团队开发的一款 JS 的单元测试工具。简单、易上手,功能全,支持多种模式的 mock,内置了测试覆盖率生成的功能
常用哪几种 mock ?
- 依赖/包的 mock
- 依赖中某个方法的 mock
写单元测试一定要用好 mock 功能,单元测试用例要关注你要测试功能即可,对其他无关的依赖和函数,可以通过 mock 来返回指定你想要的数据
cypress
是一款自动化的、集成 UI 测试工具,通过编写代码的测试用例,它会使用一个客户端来运行你的前端代码,并模拟用户的交互进行测试
集成测试和单元测试的区别
- 单元测试是测试你的一个小的功能模块,可以随时、随地、不受环境的限制去运行的
- 集成测试是在一个类似生产环境下测试你的功能模块,和单元测试相比,集成测试更多的是关注业务功能和用户交互的角度上去进行测试
mqtt
MQTT(Message Queuing Telemetry Transport,消息队列遥测传输协议),是一种基于发布/订阅(publish/subscribe)模式的"轻量级"通讯协议
可以在弱网环境下使用,常用在物联网
mqtt 和 rabitmq 的区别
storybook
它是一个面向前端 UI 组件库的文档和测试工具,它可以通过一种类似 .md 格式的文件,去渲染组件文档,文件里是支持你使用一些 js 的语法和语句,比如可以导入你想要表达的组件,然后配置一些 JSON 数据,并且可以在文档里面去使用对应的组件,storybook 就会根据 .mdx 文件去进行渲染文档,用户可以在页面对组件进行交互,比如修改组件的传入参数,捕获事件的回调等等
优点:
- 更友好、直观的组件文档,它提供了在线修改组件属性的功能
- 文档齐全,配置简单,有丰富的生态,支持 react, vue, angular 等常用框架
- 有配套的 UI 测试工具
- 独立构建资源,不和项目的构建方式关联