常用匹配
获取两个字符之间的内容
获取某个字符之前的字符串:
str.match(/(\S*)a/)[1]获取某个字符之后的字符串:
str.match(/a(\S*)/)[1]获取两个字符串之间的字符串:
str.match(/a(\S*)b/)[1]每隔三位整数插入 ‘,’:
/(?!^)(?=(\d{3})+$)/g- (?=(\d{3})+$) 这部分,从末尾算起,每隔三位字符,在它前面的位置插入 ‘,’
- (?!^) 这部分是防止 ‘,’ 开头
格式化小数:
str.replace(/\B(?=(\d{3})+\b)/g, ‘,’)- 添加了 \b ,设置三个数字的边界,并且忽略 . 号
- ?= 匹配到这三个数字前面的位置
- \B 匹配非单词之间的位置
去除前后的空格:
/(^\s+)|(\s+$)/g单词首字母转为大写:
/((?:^|\s)[a-z])/gjavascript// 匹配任意字母开头或者 \s // ...不太懂 const reg = /((?:^|\s)[a-z])/g console.log('sdf sdf qe vd ed er '.replace(reg, function(str) { console.log(str) return str.toUpperCase() }))驼峰化:
/[-_\s]+(.)?/gjavascript// 先任意匹配 -_\s ,后接某个字符 // 正则后面的 ? 的目的,是为了应对 str 尾部的字符可能不是单词字符,比如 str 是 '-moz-transform ' function camelize (str) { return str.replace(/[-_\s]+(.)?/g, function (match, c) { return c ? c.toUpperCase() : ''; }); } console.log( camelize('-moz-transform') ); // => "MozTransform"匹配颜色:
/(\((([0-9]{1,2})|(1[0-9]{2})|(2[0-5][0-6])),\s?(([0-9]{1,2})|(1[0-9]{2})|(2[0-5][0-6])),\s?(([0-9]{1,2})|(1[0-9]{2})|(2[0-5][0-6]))(,\s?([0-9]|(0?\.[0-9]{1,2})))?\))|(\#([a-zA-X0-9]{6}|[a-zA-X0-9]{3,4}))/gjavascriptconst reg = /(\((([0-9]{1,2})|(1[0-9]{2})|(2[0-5][0-6])),\s?(([0-9]{1,2})|(1[0-9]{2})|(2[0-5][0-6])),\s?(([0-9]{1,2})|(1[0-9]{2})|(2[0-5][0-6]))(,\s?([0-9]|(0?\.[0-9]{1,2})))?\))|(\#([a-zA-X0-9]{6}|[a-zA-X0-9]{3,4}))/g console.log('(23,16,7) (1, 34, 257, 1) (1, 34, 255, 0.1) (1, 34, 255, 0.01) #123 (23,34, 63) #1234 #12345 #123456'.match(reg))
学习
概念
正则表达式是匹配模式,要么匹配字符,要么匹配位置
横向模糊匹配:一个正则可匹配的字符串的长度不是固定的,可以是多种情况的
纵向模糊匹配:一个正则匹配的字符串,具体到某一位字符时,它可以不是某个确定的字符,可以有多种 可能
位置:
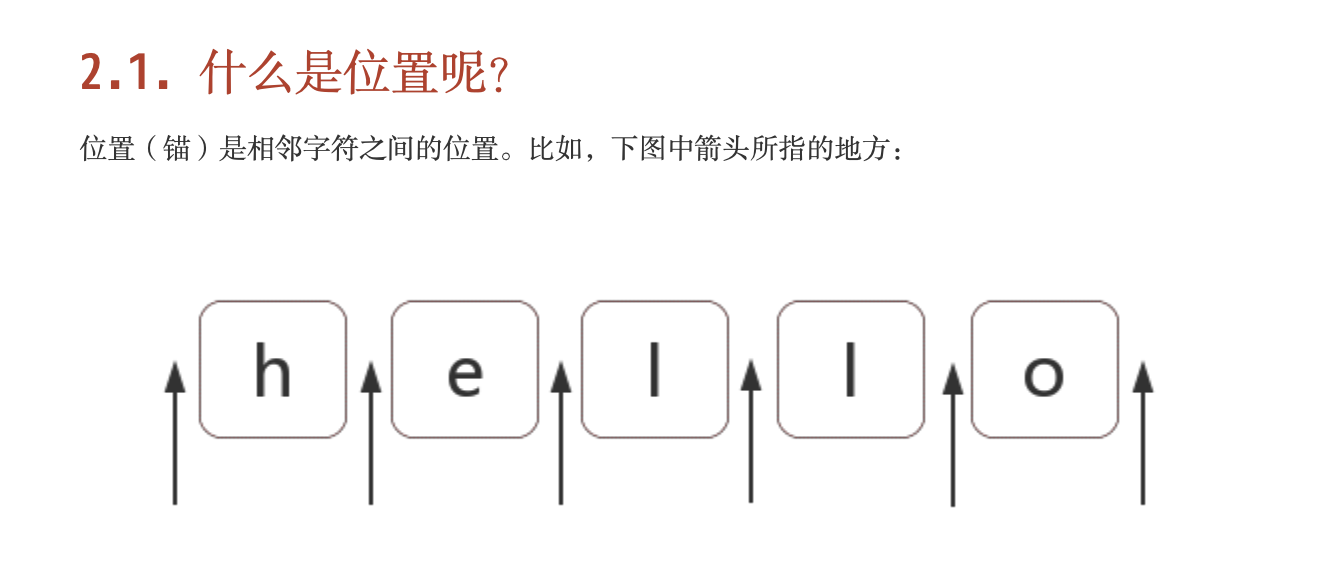
(?=p),简单点就是匹配 p 前面的位置(是位置,不是字符)
(?!p) 和 (?=p) 相反,匹配 p 前面的位置之外的地方
\b 是单词边界,具体就是 \w 与 \W 之间的位置,也包括 \w 与 ^ 之间的位置,和 \w 与 $ 之间的位置。
\B 就是 \b 的反面的意思,非单词边界。例如在字符串中所有位置中,扣掉 \b,剩下的都是 \B 的。 具体说来就是 \w 与 \w、 \W 与 \W、^ 与 \W,\W 与 $ 之间的位置。
分组:
要将 yyyy-mm-dd 转换成 mm/dd/yyyy
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, "$2/$3/$1"); console.log(result);
// => "06/12/2017"
// ---
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function () {
return RegExp.$2 + "/" + RegExp.$3 + "/" + RegExp.$1; });
console.log(result);
// => "06/12/2017"
// ---
var regex = /(\d{4})-(\d{2})-(\d{2})/;
var string = "2017-06-12";
var result = string.replace(regex, function (match, year, month, day) {
return month + "/" + day + "/" + year;
});
console.log(result);
// => "06/12/2017"反向引用
var regex = /\d{4}(-|\/|\.)\d{2}\1\d{2}/; var string1 = "2017-06-12";
var string2 = "2017/06/12";
var string3 = "2017.06.12";
var string4 = "2016-06/12";
console.log( regex.test(string1) ); // true console.log( regex.test(string2) ); // true console.log( regex.test(string3) ); // true console.log( regex.test(string4) ); // false注意正则有这样的声明:\1
\1 这个声明,指向第一个分组的规则,也就是 (-|/|\.)
当第一个分组匹配到 -,那 \1 就是指向 -;同理,第一个分组匹配到什么内容,那 \1 就是要匹配什么内容
再复杂点,多个嵌套分组:/^((\d)(\d(\d)))\1\2\3\4$/
匹配的分组,其实就从 ( 这个开始数起
\10 还是匹配第十个分组,而不是第一个分组 + 0
如果分组不在,就对这个数字转义
回溯
回溯法也称试探法,它的基本思想是:从问题的某一种状态(初始状态)出发,搜索从这种状态出发 所能达到的所有“状态”,当一条路走到“尽头”的时候(不能再前进),再后退一步或若干步,从 另一种可能“状态”出发,继续搜索,直到所有的“路径”(状态)都试探过。这种不断“前进”、 不断“回溯”寻找解的方法,就称作“回溯法”。
— 百度百科
会造成回溯的正则:
- 贪婪量词,{1, n}
- 惰性量词,{1, n}?
- 分支结构,a|b
回溯,在我学习后的理解:正则在匹配到某个位置或字符的时候,发现不匹配,它会从新回到某个位置用另外的规则去进行匹配
因为一个正则,拆解后会有不同的分支、量词等,这些都是可能会造成回溯
非捕获型分组
(ab): 捕获型分组。把 "ab" 当成一个整体,比如 (ab)+ 表示 "ab" 至少连续出现一次。
(?:ab): 非捕获型分组。与 (ab) 的区别是,它不捕获数据。
优化
优化的前提是确保正确性;但是优化也有可能造成可读性差的问题
使用具体型字符组来代替通配符,来消除回溯
使用非捕获型分组
因为括号的作用之一是,可以捕获分组和分支里的数据。那么就需要内存来保存它们。
当我们不需要使用分组引用和反向引用时,此时可以使用非捕获分组。
独立出确定字符
/a+/ 可以修改成 /aa*/
反正就是把能确定的字符,具体表现出来
提取分支公共部分
/this|that/ 修改成 /th(?:is|at)/
减少分支的数量,缩小它们的范围
/red|read/ 可以修改成 /rea?d/
注意事项
小心 g
全局匹配符有个陷阱,多次匹配同一个字符串,可能会出现不同的结果
引用 mdn 文档说明:
如果正则表达式设置了全局标志,
test()的执行会改变正则表达式lastIndex属性。连续的执行test()方法,后续的执行将会从 lastIndex 处开始匹配字符串,(exec()同样改变正则本身的lastIndex属性值).
const reg = /hi/g
console.log(reg.test('hi')) true
console.log(reg.test('hi')) false
console.log(reg.test('hi')) true三次检验的结果,不一样
这里说明下 lastIndex ,这个是 RegExp 对象的属性,只当使用了 g 的时候,才会有用
lastIndex是正则表达式的一个可读可写的整型属性,用来指定下一次匹配的起始索引。
具体规则:
- 如果
lastIndex大于字符串的长度,则regexp.test和regexp.exec将会匹配失败,然后lastIndex被设置为 0。- 如果
lastIndex等于字符串的长度,且该正则表达式匹配空字符串,则该正则表达式匹配从lastIndex开始的字符串。(then the regular expression matches input starting atlastIndex.)- 如果
lastIndex等于字符串的长度,且该正则表达式不匹配空字符串 ,则该正则表达式不匹配字符串,lastIndex被设置为 0.。- 否则,
lastIndex被设置为紧随最近一次成功匹配的下一个位置。
下面解释下每种情况的逻辑:
const reg = /hi/g
console.log(reg.lastIndex, reg.test('hi')) // 0 true
console.log(reg.lastIndex, reg.test('hi')) // 2 false;触发了第三条规则,匹配失败,然后 lastIndex 设置为 0;因为 test 方法是从 lastIndex 开始匹配,所以从第三位字符串匹配的时候,失败了
console.log(reg.lastIndex, reg.test('hi')) // 0 true
console.log(reg.lastIndex) // 2const reg = /\w*/g
console.log(reg.lastIndex, reg.test('hi')) // true
console.log(reg.lastIndex, reg.test('1hi')) // 2 true
console.log(reg.lastIndex, reg.test('hi')) // 3 false;触发第一条规则,lastIndex 大于字符串长度,所以变位0,且失败
console.log(reg.lastIndex) // 0使用 g 时,尽量不要缓存该正则